Seite 1 von 3
Trenderkennung
Verfasst: Do Sep 14, 2017 10:09 am
von wkowalski
Hallo!
Ich beschäftige mich momentan mit der Trenderkennung von Datensätzen. Konkret handelt es sich um Erkrankungsraten für verschiedene Krankheiten innerhalb der männlichen und weiblichen Bevölkerung für bestimmte Jahre.
Die Daten sehen in etwa so aus:
Berichtsjahr Erkrankungsrate
1989 1948
1990 2219
1991 1999
1992 2201
1993 2138
1994 2179
1995 1944
Das Ziel sollte nun sein, herauszufinden ob man aus diesen Daten einen Trend "herauslesen" und diesen dann fortführen kann. Beispielsweise habe ich ein lineares Modell entwickelt, welches mir eine lineare Hochrechnung für die nächsten Jahre berechnet. Problem hierbei ist, dass ich nicht weiß ob die hier die lineare Hochrechnung die beste und Genaueste Variante darstellt. Weiters sind die Datensätze auch sehr beschränkt -> ich habe nur Daten im Zeitraum von 1989 - 2014. Habt ihr vielleicht eine Idee, wie ich da am besten Verfahren könnte?
LG
Re: Trenderkennung
Verfasst: Do Sep 14, 2017 10:48 am
von consuli
Schritt 1)
Deine Absolutzahlen in echte Raten umrechnen. Wenn die Krankheit z.B. Alzheimer wäre, durch die Anzahl der Risikogruppe z.B. älter 65 Jahre, teilen.
Schritt 2)
XY Plott, echte Rate über Zeit.
Schritt 3)
Anhand des XY Plots ein in Frage kommende Modell auswählen.
Schritt 4)
Ausgewählte Modelle (3 bis 5) auf die (wenigen Datenpunkte) anfitten.
Schritt 5)
Anhand der R-Quadrat Statistik das Modell auswählen, dass die kleinste Quadratemethode als Optimierungsmethode verwendet hat, weil R-Quadrat ebenfalls auf kleinster Quadrate Methode aufgebaut ist.


Re: Trenderkennung
Verfasst: Do Sep 14, 2017 10:55 am
von wkowalski
Zu 1.)
Sorry habe die falschen Daten reinkopiert: natürlich sollten es keine Absolutzahlen sein
Das Ganze sieht dann so aus:
Jahr Erkrankungsrate
1989 0,004126305
1990 0,003389681
1991 0,005452984
1992 0,004367897
1993 0,006365385
1994 0,005945599
1995 0,006688963
2.) Das Problem ist, dass ich wirklich viele Datensätze habe -> sprich es gibt für einzelne Erkrankungen verschiedene Altersgruppen (von 0-95+ Jahre) das heißt ich hab 40 Files mit je 95+ Spalten. Wenn ich mir da jede Altersgruppe einzeln anschauen muss werd ich wahrscheinlich verrückt

Zu 3.) und 4.) das muss ich mir dann also nochmal ansehen
Irgendeine Idee wie ich am besten starte?
LG
Re: Trenderkennung
Verfasst: Do Sep 14, 2017 5:33 pm
von consuli
wkowalski hat geschrieben: ↑Do Sep 14, 2017 10:55 am
Zu 3.) und 4.) das muss ich mir dann also nochmal ansehen
Genau. Kannst dann ja mal ein paar x-y-plots posten. Daraus ergibt sich dann das weitere Vorgehen.
Re: Trenderkennung
Verfasst: Fr Sep 22, 2017 2:38 pm
von wkowalski
Hallo!
Habe jetzt mal für Herzkreislauferkrankungen ein paar Plots erstellt:
Hier mal ein Plot für 1jährige Männer in den Jahren von 1989 - 2014
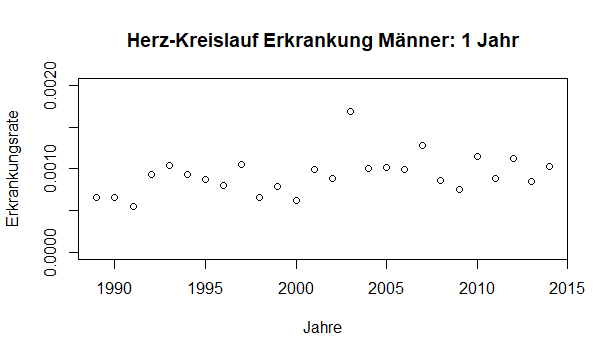
- m1.png (4.61 KiB) 1736 mal betrachtet
Dann noch ein Plot für 50 jährige Männer
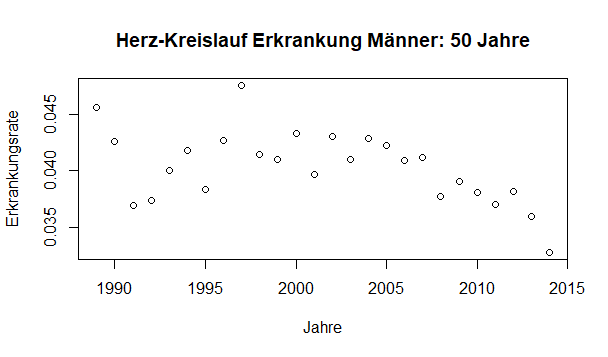
- m50.png (4.81 KiB) 1736 mal betrachtet
Leider kann ich nur 2 Dateien anhängen --> habe allerdings noch ein paar Plots gemacht
LG
Re: Trenderkennung
Verfasst: Fr Sep 22, 2017 5:34 pm
von EDi
consuli hat geschrieben: ↑Do Sep 14, 2017 10:48 am
Schritt 1)
Deine Absolutzahlen in echte Raten umrechnen. Wenn die Krankheit z.B. Alzheimer wäre, durch die Anzahl der Risikogruppe z.B. älter 65 Jahre, teilen.
Hmm, sind die Raten dann normalverteilt? Ich vermute nicht...
Wie wäre es mit einem GLM (Poisson, negativ binomial) mit der Größe der Risikogrupoe als Offset? Dann bekommt man wenigstens keine Nonsense vorhersagen...
Re: Trenderkennung
Verfasst: Fr Sep 22, 2017 9:46 pm
von bigben
Hi!
Ich sehe jeweils wenige Punkte und viel Streuung. Sehr viel Information über die Art des Trends steckt da nicht drin und eine gute Theorie haben wir nicht. Wenn man da mehr als eine Gerade durch legt, dann schreit man nach Overfitting. Selbst die Gerade würde ich lieber mit robuster Regression statt LOS gerechnet sehen.
JMTC,
Bernhard
Re: Trenderkennung
Verfasst: Mo Sep 25, 2017 3:54 pm
von wkowalski
Hey!
Wie soll ich den Datensatz auf Normalverteilung überprüfen? Mit Shapiro-Wilk?
Ja die wenigen Punkte stellen auf jeden Fall ein Problem dar das weiß ich. Gibt es nicht eine Möglichkeit einen Trend herauszufinden der nicht kompletter Blödsinn oder geraten ist?
Re: Trenderkennung
Verfasst: Mo Sep 25, 2017 4:20 pm
von bigben
Hi!
Gibt es einen Grund, auf Normalverteilung zu prüfen? Wenn Du wirklich viele DAtensätze hast, die alle normalverteilt sind, dann ist bei jedem 20. trotzdem p < 0.05.
Mein Vorschlag wäre einen Trend als Regressionsgerade einer robuste linearen Regression zu errechnen. OLS ist sehr anfällig gegenüber Ausreißern.
LG,
Bernhard
Re: Trenderkennung
Verfasst: Mo Sep 25, 2017 4:53 pm
von wkowalski
Ok bezüglich Normalverteilung wollte ich nur auf den Kommentar von EDi reagieren
bigben hat geschrieben: ↑Mo Sep 25, 2017 4:20 pm
Mein Vorschlag wäre einen Trend als Regressionsgerade einer robuste linearen Regression zu errechnen. OLS ist sehr anfällig gegenüber Ausreißern.
O.k ich werd mir die robuste lineare Regression mal genauer ansehen...
Ist die robuste lineare Regression von der Anwendung her ähnlich der normalen linearen Regression?
LG