Seite 1 von 2
Outlier Detection bei großer Datenmenge
Verfasst: Mo Mär 30, 2020 6:10 am
von Tom
Hallo zusammen,
weiß jemand, wie ich am besten bei einem großen Datensatz Ausreißer mit R-Studio bestimmen kann?
Danke schonmal im Voraus für Eure Hilfe

Re: Outlier Detection bei großer Datenmenge
Verfasst: Mo Mär 30, 2020 7:58 am
von bigben
Es gibt keine allgemeine Definition des Ausreißers und deshalb auch keine eindeutige Antwort auf Deine Frage. Manche verwenden die Definition aus dem Boxplot. Kommt das für Dich infrage?
LG Bernhard
Re: Outlier Detection bei großer Datenmenge
Verfasst: Mo Mär 30, 2020 9:27 am
von student
Hallo Tom,
ich verwende lieber den Begriff
Extremwert als
Ausreißer. Extremwert finde ich angemessener, weil er für ein seltenes aber dennoch wahrscheinliches Ereignis steht. Das bedeutet, dass z .B. das Entfernen von Extremwerten aus den Beobachtungen
erklärt und
dokumentiert werden muss.
Einer meiner ersten Datenanalyseschritten ist die Visualisierung (wie der erwähnte Boxplot) und dann abhängig vom Bild der Verteilung gehe ich dann tiefer, bis hin zu den Extremwerten (wenn sie möglicherweise vorhanden sind.)
Ich gehe natürlich davon aus, dass Du die Daten
validiert hast.
Re: Outlier Detection bei großer Datenmenge
Verfasst: Mo Mär 30, 2020 11:47 am
von bigben
"Extremwert" finde ich schwierig - bei der Kurvendiskussion im Mathematikunterricht waren das lokale Maximum und das lokale Minimum Extremwerte.
Die Bedeutung einer visuellen Beurteilung der Daten ist natürlich enorm. Man kann sich aber auch vorstellen, dass es Situationen gibt, in denen man einen Algorithmus zum Erkennen von Ausreißern braucht. Boxplots liefern eben nicht nur eine weit verbreitete Art der visuellen Inspektion, sondern auch einen gängigen Algorithmus zu identifizieren von Ausreißern
Code: Alles auswählen
set.seed(as.Date("30-03-2020"))
messungen <- c(10*rbeta(100, 1,5), 9.5,10)
plot(density(messungen), ylim=c(0,.9), main="")
boxplot(messungen, horizontal = TRUE, at=.7, add=TRUE, boxwex = .5)
rug(messungen)
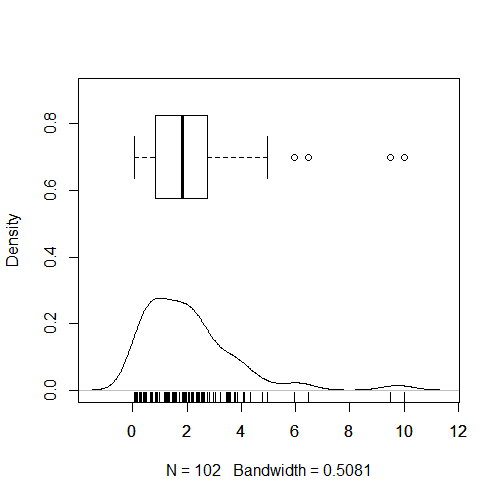
- Rplot.png (4.22 KiB) 902 mal betrachtet
Die Hälfte der Werte ist in den Box, die andere Hälfte im Bereich der Whiskers und vier Werte sind automatisch/algorothmisch als Ausreißer erkannt und als Kreise im Boxplot dargestellt. Man mag im Einzelfall darüber streiten, ob das eine sinnvoller Algorithmus ist, oder nicht. In der Masse der denkbaren ist er sicherlich einer der bekanntesten. Die Ausreißerwerte gehören zum Rückgabewert der Funktion histogram:
Mit dem Argument range lässt sich auch einstellen, ob man empfindlicher oder unempfindlicher sein möchte. Hier vier Histogramme vom gleichen Datensatz mit 4 verschiedenen range -Werten:
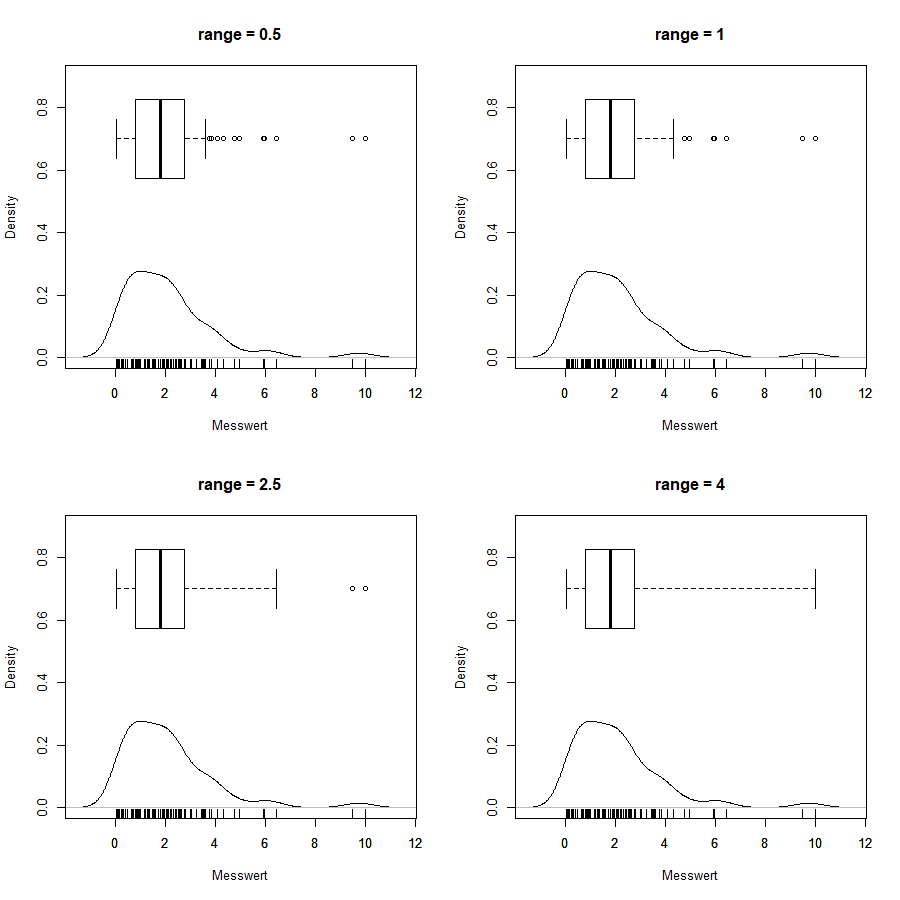
- Rplot01.png (10.78 KiB) 900 mal betrachtet
HTH,
Bernhard
Re: Outlier Detection bei großer Datenmenge
Verfasst: Mo Mär 30, 2020 3:32 pm
von student
Mit
"Extremwert" finde ich schwierig - bei der Kurvendiskussion im Mathematikunterricht waren das lokale Maximum und das lokale Minimum Extremwerte.
hast Du recht, ich meine natürlich Extremwert im Kontext "Statistik".

Deine Beschreibung im Umgang mit
Extremwerten (
) ist recht anschaulich, entspricht auch meiner Erfahrung: Leider habe ich erlebt, dass solange mit den Parametern experimentiert wurde, bis es passte (= so kann ich es gebrauchen, um ....). Oftmals wurde das Info-Potenzial ausgeblendet, dass in
Extremwerten steckt. Aber damit möchte ich keine
Extremwert-/Ausreißer-Diskussion lostreten, ich habe nur meine 2 Cent zum Besten gegeben!
Re: Outlier Detection bei großer Datenmenge
Verfasst: Mo Mär 30, 2020 3:40 pm
von bigben
Hallo Günther,
ich finde es gar nicht falsch, eine Ausreißer-Diskussion zu führen. Im Statistik-Forum hat 2016 mal jemand gefragt, ob er seine Ausreißer löschen soll und ich zitiere jetzt einfach mal meine Antwort im anderen Forum, auch wenn ich nicht weiß, ob das dem Hintergedanken des OP entspricht:
Die von Dir aufgeworfene Frage ist hoch komplex und kann nicht mit einem simplen Schema beantwortet werden. Extreme Werte können unsinnig entstandene Werte sein (Messwert falsch auf den Erhebungsbogen übertragen) oder das Ergebnis einer tatsächlichen Streuung der Messgröße sein. In Fukushima hatte man Mauern gegen 5,5m hohe Wellen gebaut. Dann kam die 10m hohe Welle. Sie war ein Extremwert, aber einer, den das Meer tatsächlich produziert hat. Die 10m Welle war real und es wäre verfälschend, sie aus den Archiven streichen zu wollen. Hätte aber jemand versehentlich eine 10cm Welle als 10m Welle dokumentiert, dann müsste man diesen offensichlich falschen Wert aus den Messungen streichen. Das hat gar nichts damit zu tun, welchen z-Wert eine 10m-Welle vor Fukushima hat.
Es muss also um die Frage gehen, wie es am wahrscheinlichsten zu den extremen Werten gekommen ist und ob man den kleineren Fehler macht, wenn man sie streicht oder ob man den kleineren Fehler macht, wenn man sie drin lässt (eine zu hohe Mauer für Fukushima wäre teuer gewesen. Eine zu niedrige war fatal). Ohne Sachkunde in Ozeanographie, Hydrologie, Physik und Katastrophenschutz lässt sich die Frage nach der angemessenen Mauerhöhe nicht beantworten. Auch wir werden Deine Frage nicht beantworten können, ohne die Hintergründe genauestens zu kennen. Ohne sachwissenschaftlichen Hintergrund kann man Dir da nicht anständig raten.
(
http://www.statistik-forum.de/post26808.html )
LG,
Bernhard
Re: Outlier Detection bei großer Datenmenge
Verfasst: Mo Mär 30, 2020 4:30 pm
von Tom
bigben hat geschrieben: ↑Mo Mär 30, 2020 7:58 am
Manche verwenden die Definition aus dem Boxplot. Kommt das für Dich infrage?
Danke für Eure schnellen Antworten. Mein Problem ist hauptsächlich, dass ich die Ausreißer nicht grafisch erkennen kann, weil ich bspw. für ein Scatterplot oder Boxplot zu viele "Datenpunkte" habe, sodass mir dann überhaupt nichts angezeigt wird (stattdessen erhalte ich eine Fehlermeldung, dass es aufgrund der Datenmenge nicht angezeigt werden kann). Bei kleineren Datenmengen weiß ich, wie sich Ausreißer am besten erkennen lassen, allerdings besteht meine Variable aus über 2000 Fällen...
Re: Outlier Detection bei großer Datenmenge
Verfasst: Mo Mär 30, 2020 7:30 pm
von EDi
Tom hat geschrieben: ↑Mo Mär 30, 2020 4:30 pm
bigben hat geschrieben: ↑Mo Mär 30, 2020 7:58 am
Manche verwenden die Definition aus dem Boxplot. Kommt das für Dich infrage?
Danke für Eure schnellen Antworten. Mein Problem ist hauptsächlich, dass ich die Ausreißer nicht grafisch erkennen kann, weil ich bspw. für ein Scatterplot oder Boxplot zu viele "Datenpunkte" habe, sodass mir dann überhaupt nichts angezeigt wird (stattdessen erhalte ich eine Fehlermeldung, dass es aufgrund der Datenmenge nicht angezeigt werden kann). Bei kleineren Datenmengen weiß ich, wie sich Ausreißer am besten erkennen lassen, allerdings besteht meine Variable aus über 2000 Fällen...

Also ich kann auf meinem alten notebook (8GB RAM) einen vektor mit 100 Millionen Einträgen durchjagen
Code: Alles auswählen
x <- rlnorm(100000000)
bp <- boxplot(x, plot = FALSE)
bp$stats
Re: Outlier Detection bei großer Datenmenge
Verfasst: Di Mär 31, 2020 9:30 am
von bigben
Tom hat geschrieben: ↑Mo Mär 30, 2020 4:30 pm
bigben hat geschrieben: ↑Mo Mär 30, 2020 7:58 am
Manche verwenden die Definition aus dem Boxplot. Kommt das für Dich infrage?
Danke für Eure schnellen Antworten. Mein Problem ist hauptsächlich, dass ich die Ausreißer nicht grafisch erkennen kann, weil ich bspw. für ein Scatterplot oder Boxplot zu viele "Datenpunkte" habe, sodass mir dann überhaupt nichts angezeigt wird (stattdessen erhalte ich eine Fehlermeldung, dass es aufgrund der Datenmenge nicht angezeigt werden kann). Bei kleineren Datenmengen weiß ich, wie sich Ausreißer am besten erkennen lassen, allerdings besteht meine Variable aus über 2000 Fällen...
Mir ist so, als ob Du meine Frage nicht beantwortet hast. Einen Boxplot von 2000 Fällen zeichnet R schneller als Du blinzeln kannst
Und für große Datenmengen hatte ich extra geschrieben, dass es mir nicht um den Plot, sondern um den Algorithmus geht und auch Code gezeigt, wie man der Funktion boxplot die Ausreißer entlockt, ohne eine Grafik zu zeichnen.
zu viele "Datenpunkte" habe, sodass mir dann überhaupt nichts angezeigt wird
Versuch bitte mal folgenden Code
Code: Alles auswählen
plot(rnorm(2000), rnorm(2000), col="#000000A0", pch=16)
und ändere Deine Meinung darüber, ob R 2000 Datenpunkte zeichnen kann oder poste wörtlich die dabei entstehende Fehlermeldung.
Also nochmal: Ist der Boxplot-Algorithmus (mehr als 1,5 IQR entfernt vom Median) für Dich inhaltlich brauchbar?
Gruß,
Bernhard
Re: Outlier Detection bei großer Datenmenge
Verfasst: Di Mär 31, 2020 9:35 am
von student
Hallo Bernhard,
das ist doch eine sehr schöne Beschreibung, besonders der Vergleich einer 10m oder 10cm hohen Mauer. Das ist Domainwissen und ohne dieses Wissen, ist das Identifizieren und der Umgang möglicher Extremwerte schwerlich möglich.
Hallo Tom,
allerdings besteht meine Variable aus über 2000 Fällen...
ist wirklich kein großer Datensatz. Ich habe mal einen Boxplot mit Beobachtungen aus einem meiner
Lieblingsspieldatensätze gemacht. Er besteht aus
6497 Beobachtungen z. B. für das Merkmal
Alkohol. Der Boxplot zeigt mit den Standardparametern 3 Extremwerte. Diese Extremwerte sind aber keine Ausreißer, sondern wesentliche Informationen und dürfen nicht einfach entfernt werden (Grafik Tabelle). Mögliche Maßnahmen will ich gar nicht beschreiben...
Also kurzum, Dein Boxplot-Problem beruht auf ein anderes Problem.